Exit Synology
I have/had a Synology DS916+ NAS. This is an Intel based NAS with 4 disk bays, running on Synology’s Disk Station Manager - a nice piece of software that offers an easy way to manage the device, and run additional software on top of it.
The reason I picked this device was because my experiences with Synology had been very good in the past, and I thought I could trust Synology with my data. The added features of the software and ease of use were nice, too.
(as always, you do need to have backups of your important data - I practice the 3-2-1 backup strategy).
My configuration was pretty standard - 4 disks in a Synology Hybrid RAID (SHR), a variant of RAID 5 which allowed for easy resizing of the RAID array when bigger disks are inserted.
On top of that I used btrfs, a Copy-On-Write (COW) modern filesystem that is supposed to solve all kind of issues with respect to pooling, snapshots, …
This filesystem is also a prerequisite if you want to use Synology’s Virtual Machine Manager, a hypervisor that allows you to run virtual machines on top of your NAS. A handy addition to run some low-end VM’s.
This ran pretty smoothly for about two years and ten months.
Unfortunately, a few weeks back I got woken up by the alert buzzer of the NAS, and a not-so-nice email in my inbox:
Volume 1 (NAS) on NAS has crashed
Dear user,
Because volume 1 (NAS) on NAS has crashed, it is possible that more files may be corrupted under this circumstance. Please go to Storage Manager > Volume for more information.
Sincerely, Synology DiskStation
Ummmm….
Looking in DSM:
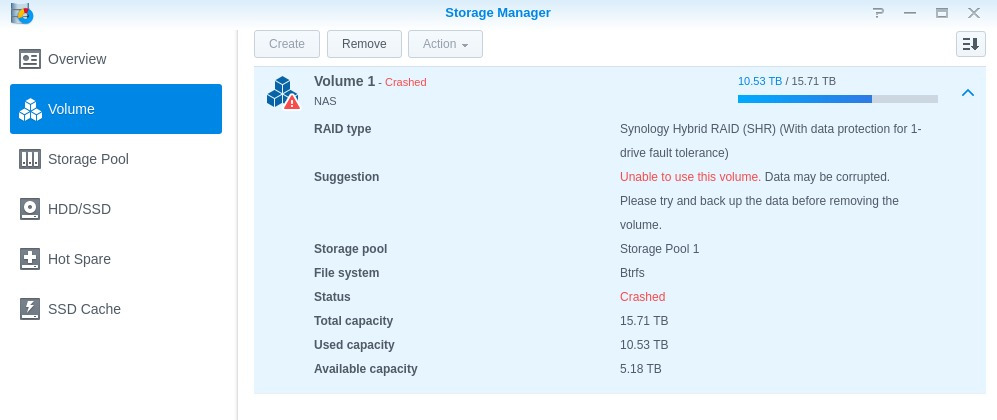
First I thought it might be a drive that had crashed, but nope:
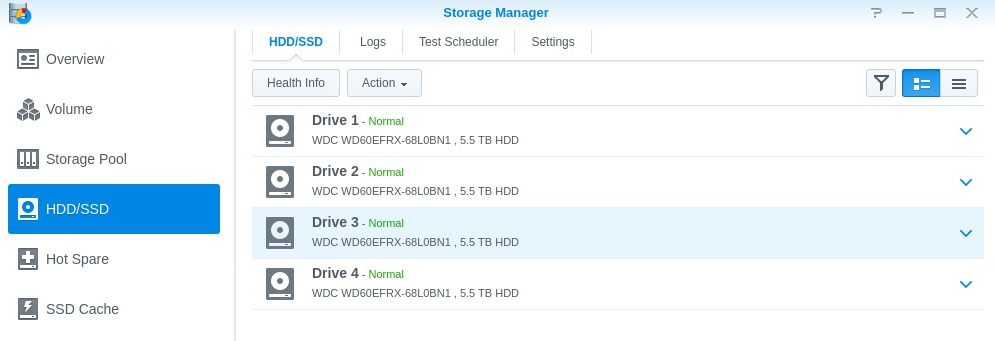
F U C K.
Checking the volume itself, half of my stuff was reachable through CIFS/NFS, most of it just hung or errored out.
Double F.
Checking on the NAS itself (through SSH), I got greeted with a plethora of beautiful errors:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
[ 167.232649] BTRFS critical (device dm-0): corrupt node, bad key order: block=9652607500288, root=1, slot=0
[ 167.243484] md/raid:md2: syno_raid5_self_heal_retry_read(7178): No suitable device for self healing retry read at sector 17769522016 (leng:8, retry: 2/2, request_cnt:3)
[ 167.260348] md/raid:md2: syno_raid5_self_heal_retry_read(7178): No suitable device for self healing retry read at sector 17769522024 (leng:8, retry: 2/2, request_cnt:3)
[ 167.277210] md/raid:md2: syno_raid5_self_heal_retry_read(7178): No suitable device for self healing retry read at sector 17769522032 (leng:8, retry: 2/2, request_cnt:3)
[ 167.294069] md/raid:md2: syno_raid5_self_heal_retry_read(7178): No suitable device for self healing retry read at sector 17769522040 (leng:8, retry: 2/2, request_cnt:3)
[ 167.310951] BTRFS critical (device dm-0): corrupt node, bad key order: block=9652607500288, root=1, slot=0
[ 167.321770] BTRFS error (device dm-0): BTRFS: dm-0 failed to repair btree csum error on 9652607500288, mirror = 1
...
[ 213.112600] ------------[ cut here ]------------
[ 213.117815] WARNING: at fs/btrfs/super.c:263 __btrfs_abort_transaction+0xe5/0x130 [btrfs]()
[ 213.127235] BTRFS: Transaction aborted (error -5)
[ 213.127240] Modules linked in: pci_stub vhost_net tun kvm_intel kvm vhost_scsi(O) vhost(O) bridge stp aufs macvlan veth xt_conntrack xt_addrtype wireguard(OF) ipt_MASQUERADE xt_REDIRECT xt_nat iptable_nat nf_nat_ipv4 nf_nat tcm_loop(O) iscsi_target_mod(O) target_core_ep(O) target_core_multi_file(O) target_core_file(O) target_core_iblock(O) target_core_mod(O) syno_extent_pool(PO) rodsp_ep(O) cifs udf isofs loop nfsd exportfs rpcsec_gss_krb5 syno_hddmon(P) hid_generic usbhid hid usblp usb_storage uhci_hcd ehci_pci ehci_hcd nf_conntrack_ipv6 ip6table_filter ip6_tables xt_recent xt_iprange xt_limit xt_state xt_tcpudp xt_multiport xt_LOG nf_conntrack_ipv4 nf_defrag_ipv4 iptable_filter ip_tables x_tables openvswitch(O) gre nf_defrag_ipv6 nf_conntrack braswell_synobios(PO) leds_lp3943 exfat(O) btrfs i915
[ 213.207696] drm_kms_helper cfbfillrect cfbcopyarea cfbimgblt output drm fb fbdev intel_agp intel_gtt agpgart video backlight button synoacl_vfs(PO) zlib_deflate hfsplus md4 hmac libcrc32c compat(O) igb(O) i2c_algo_bit e1000e(O) vxlan fuse vfat fat crc32c_intel aesni_intel glue_helper lrw gf128mul ablk_helper arc4 cryptd ecryptfs sha256_generic sha1_generic ecb aes_x86_64 authenc des_generic ansi_cprng cts md5 cbc cpufreq_powersave cpufreq_performance acpi_cpufreq mperf processor thermal_sys cpufreq_stats freq_table dm_snapshot crc_itu_t crc_ccitt quota_v2 quota_tree psnap p8022 llc sit tunnel4 ip_tunnel ipv6 zram(C) sg etxhci_hcd xhci_hcd usbcore usb_common [last unloaded: braswell_synobios]
[ 213.275995] CPU: 3 PID: 16772 Comm: abk-agent-serve Tainted: PF C O 3.10.105 #24922
[ 213.285272] Hardware name: Synology Inc. DS916+/Type2 - Board Product Name, BIOS M.215 3/2/2016
[ 213.295033] ffffffff814b324b ffffffff81035b08 ffff88025d751590 ffff880205dcfb90
[ 213.303384] 00000000fffffffb ffffffffa0551f40 0000000000001a61 ffffffff81035b69
[ 213.311725] ffffffffa0555f28 ffff880200000020 ffff880205dcfba0 ffff880205dcfb60
[ 213.320111] Call Trace:
[ 213.322859] [<ffffffff814b324b>] ? dump_stack+0xc/0x15
[ 213.328730] [<ffffffff81035b08>] ? warn_slowpath_common+0x58/0x70
[ 213.335740] [<ffffffff81035b69>] ? warn_slowpath_fmt+0x49/0x50
[ 213.342435] [<ffffffffa0496ac5>] ? __btrfs_abort_transaction+0xe5/0x130 [btrfs]
[ 213.350816] [<ffffffffa04ab548>] ? __btrfs_free_extent+0x338/0xd80 [btrfs]
[ 213.358665] [<ffffffffa0519c5d>] ? find_ref_head+0x5d/0x80 [btrfs]
[ 213.365711] [<ffffffffa04b1153>] ? __btrfs_run_delayed_refs+0x453/0x11d0 [btrfs]
[ 213.374134] [<ffffffff810b7087>] ? find_get_pages_tag+0xc7/0x1a0
[ 213.380973] [<ffffffff81059f25>] ? __wake_up_common+0x55/0x90
[ 213.387545] [<ffffffffa04b6a5c>] ? btrfs_run_delayed_refs+0xbc/0x2e0 [btrfs]
[ 213.395600] [<ffffffffa04c9edc>] ? btrfs_commit_transaction+0x3c/0xb50 [btrfs]
[ 213.403853] [<ffffffffa04e7fe2>] ? btrfs_lookup_first_ordered_extent+0x52/0xa0 [btrfs]
[ 213.412964] [<ffffffffa04e1d2d>] ? btrfs_sync_file+0x28d/0x360 [btrfs]
[ 213.420397] [<ffffffff8112f22e>] ? do_fsync+0x4e/0x80
[ 213.426201] [<ffffffff8112f4ba>] ? SyS_fdatasync+0xa/0x10
[ 213.432438] [<ffffffff814b9dc4>] ? system_call_fastpath+0x22/0x27
[ 213.439384] ---[ end trace a2b1ccbcbf5597c4 ]---
and a mass of other btrfs errors.
Logging a ticket with Synology was useless: the only thing they told me was to recreate the volume and restore from backups. WTF. Not acceptable. I also asked them for the reason what might have caused this failure. The reply that I got was that probably one or more disks failed.
First try to get the volume back was to use the btrfs check on the nas itself. This failed because the volume was still mounted, and I couldn’t get it unmounted.
Second try was with btrfs scrub, but that failed rather quickly too with an I/O error.
After this I removed the disks from the NAS and plugged them in my desktop. To rule out issues with the disks, I ran badblocks on them - nothing came out - all disks are healthy (which they should be - the MTBF of WD Red drives is a lot higher than the lifetime I’ve had them).
Second try with btrfs check, but again, no dice. btrfs restore managed to get some things back, but not many - nothing more than when I mounted the filesystem readonly and copied off the things that I could.
I even checked with the helpful people on the #btrfs channel on Freenode, but they also didn’t see a way out. It doesn’t help that Synology uses their own fork of btrfs. It should also be noted that Synology runs btrfs on top of mdraid - something often done to get rid of the btrfs write hole when using RAID 5/6 (for which a patch was issued) - which causes btrfs to have no idea about the state of the underlying disks. This might have contributed to the issue - who knows.
Before you ask - the mdadm RAID array was also fine - no corruption there.
After digging more through the logs, I came across this:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
2020-04-19T03:01:47+02:00 cube kernel: [949231.381433] ata1: device unplugged sstatus 0x0
2020-04-19T03:01:47+02:00 cube kernel: [949231.386516] ata2: device unplugged sstatus 0x0
2020-04-19T03:01:47+02:00 cube kernel: [949231.391616] ata2.00: exception Emask 0x10 SAct 0x0 SErr 0x4090000 action 0xe frozen
2020-04-19T03:01:47+02:00 cube kernel: [949231.391779] ata4: device unplugged sstatus 0x0
2020-04-19T03:01:47+02:00 cube kernel: [949231.391802] ata4.00: exception Emask 0x10 SAct 0x0 SErr 0x190002 action 0xe frozen
2020-04-19T03:01:47+02:00 cube kernel: [949231.391804] ata4.00: irq_stat 0x80400000, PHY RDY changed
2020-04-19T03:01:47+02:00 cube kernel: [949231.391806] ata4: SError: { RecovComm PHYRdyChg 10B8B Dispar }
2020-04-19T03:01:47+02:00 cube kernel: [949231.391809] ata4.00: failed command: FLUSH CACHE EXT
2020-04-19T03:01:47+02:00 cube kernel: [949231.391814] ata4.00: cmd ea/00:00:00:00:00/00:00:00:00:00/a0 tag 27
2020-04-19T03:01:47+02:00 cube kernel: [949231.391814] res 50/00:00:00:78:a3/00:00:61:01:00/e0 Emask 0x10 (ATA bus error)
2020-04-19T03:01:47+02:00 cube kernel: [949231.391815] ata4.00: status: { DRDY }
2020-04-19T03:01:47+02:00 cube kernel: [949231.391826] ata4: hard resetting link
2020-04-19T03:01:47+02:00 cube kernel: [949231.392025] ata3: device unplugged sstatus 0x0
2020-04-19T03:01:47+02:00 cube kernel: [949231.392051] ata3.00: exception Emask 0x10 SAct 0x0 SErr 0x190002 action 0xe frozen
2020-04-19T03:01:47+02:00 cube kernel: [949231.392052] ata3.00: irq_stat 0x80400000, PHY RDY changed
2020-04-19T03:01:47+02:00 cube kernel: [949231.392054] ata3: SError: { RecovComm PHYRdyChg 10B8B Dispar }
2020-04-19T03:01:47+02:00 cube kernel: [949231.392056] ata3.00: failed command: FLUSH CACHE EXT
2020-04-19T03:01:47+02:00 cube kernel: [949231.392061] ata3.00: cmd ea/00:00:00:00:00/00:00:00:00:00/a0 tag 30
2020-04-19T03:01:47+02:00 cube kernel: [949231.392061] res 50/00:00:80:22:9e/00:00:61:01:00/e0 Emask 0x10 (ATA bus error)
2020-04-19T03:01:47+02:00 cube kernel: [949231.392062] ata3.00: status: { DRDY }
2020-04-19T03:01:47+02:00 cube kernel: [949231.392067] ata3: hard resetting link
2020-04-19T03:01:47+02:00 cube kernel: [949231.513708] ata2.00: irq_stat 0x00400040, connection status changed
2020-04-19T03:01:47+02:00 cube kernel: [949231.520817] ata2: SError: { PHYRdyChg 10B8B DevExch }
2020-04-19T03:01:47+02:00 cube kernel: [949231.526569] ata2.00: failed command: FLUSH CACHE EXT
2020-04-19T03:01:47+02:00 cube kernel: [949231.532225] ata2.00: cmd ea/00:00:00:00:00/00:00:00:00:00/a0 tag 2
2020-04-19T03:01:47+02:00 cube kernel: [949231.532225] res 50/00:00:80:44:db/00:00:32:00:00/e0 Emask 0x10 (ATA bus error)
2020-04-19T03:01:47+02:00 cube kernel: [949231.548262] ata2.00: status: { DRDY }
2020-04-19T03:01:47+02:00 cube kernel: [949231.552469] ata2: hard resetting link
2020-04-19T03:01:47+02:00 cube kernel: [949231.556733] ata1.00: exception Emask 0x10 SAct 0x0 SErr 0x4090000 action 0xe frozen
2020-04-19T03:01:47+02:00 cube kernel: [949231.565436] ata1.00: irq_stat 0x00400040, connection status changed
2020-04-19T03:01:47+02:00 cube kernel: [949231.572551] ata1: SError: { PHYRdyChg 10B8B DevExch }
2020-04-19T03:01:47+02:00 cube kernel: [949231.578300] ata1.00: failed command: FLUSH CACHE EXT
2020-04-19T03:01:47+02:00 cube kernel: [949231.583958] ata1.00: cmd ea/00:00:00:00:00/00:00:00:00:00/a0 tag 21
2020-04-19T03:01:47+02:00 cube kernel: [949231.583958] res 50/00:00:00:78:a3/00:00:61:01:00/e0 Emask 0x10 (ATA bus error)
2020-04-19T03:01:47+02:00 cube kernel: [949231.600110] ata1.00: status: { DRDY }
2020-04-19T03:01:47+02:00 cube kernel: [949231.604321] ata1: hard resetting link
2020-04-19T03:01:52+02:00 cube kernel: [949236.613438] ata2: SATA link up 6.0 Gbps (SStatus 133 SControl 300)
2020-04-19T03:01:52+02:00 cube kernel: [949236.770796] ata2.00: retrying FLUSH 0xea Emask 0x10
2020-04-19T03:01:52+02:00 cube kernel: [949236.776460] ata2.00: Write Cache is enabled
2020-04-19T03:01:52+02:00 cube kernel: [949236.877426] ata1: SATA link up 6.0 Gbps (SStatus 133 SControl 300)
2020-04-19T03:01:53+02:00 cube kernel: [949237.029855] ata1.00: retrying FLUSH 0xea Emask 0x10
2020-04-19T03:01:53+02:00 cube kernel: [949237.035533] ata1.00: device reported invalid CHS sector 0
2020-04-19T03:01:53+02:00 cube kernel: [949237.041725] ata1.00: Write Cache is enabled
2020-04-19T03:01:53+02:00 cube kernel: [949237.046431] ata3: SATA link up 6.0 Gbps (SStatus 133 SControl 300)
2020-04-19T03:01:53+02:00 cube kernel: [949237.054164] ata3.00: retrying FLUSH 0xea Emask 0x10
2020-04-19T03:01:53+02:00 cube kernel: [949237.067398] ata3.00: Write Cache is enabled
2020-04-19T03:01:53+02:00 cube kernel: [949237.144425] ata4: SATA link up 6.0 Gbps (SStatus 133 SControl 300)
2020-04-19T03:01:53+02:00 cube kernel: [949237.157638] ata4.00: retrying FLUSH 0xea Emask 0x10
2020-04-19T03:01:53+02:00 cube kernel: [949237.163315] ata4.00: device reported invalid CHS sector 0
2020-04-19T03:01:53+02:00 cube kernel: [949237.169483] ata4.00: Write Cache is enabled
All four disks disconnected from the hardware bus at the same time, causing massive btrfs corruption. After updating the Synology ticket they accepted that this was a NAS failure, and I’ve shipped the NAS to them for replacement. Luckely it’s still (just) in warranty.
While this looks like a hardware failure, I’m left with a bunch of questions:
- What exactly happened to have all disks disconnect from the bus the same time?
- Why did this happen only after nearly three years?
- Why did this manage to eat my entire btrfs volume?
- Is btrfs even production ready? This battle test would say ‘yes’, but .. I’m not sure.
Somehow I don’t feel very confident with Synology anymore. Definitely not with btrfs on the Synology boxes.
I’ll be replacing this setup with a home built NAS running ZFS on Linux. I’ve had excellent experiences with ZFS on Solaris, and what I’m reading about ZFS on Linux and FreeBSD only confirms my feelings.
Update: Synology replaced the DS916+ with a DS918+, but I decided to sell it and go forward with my custom build.